New Analyzer Models: Toxicity, Quality, & Propriety

I'm excited to announce 3 new models available in the dashboard as of today! In this post, I'll briefly go over each of them and describe some interesting use cases.
Each analyzer returns the respective scores of each label and decides on the label with the highest score. You might want to work with the scores directly if you need higher certainty before concluding if a label should apply. You can also turn some labels off if you don't want to include those in the analysis.
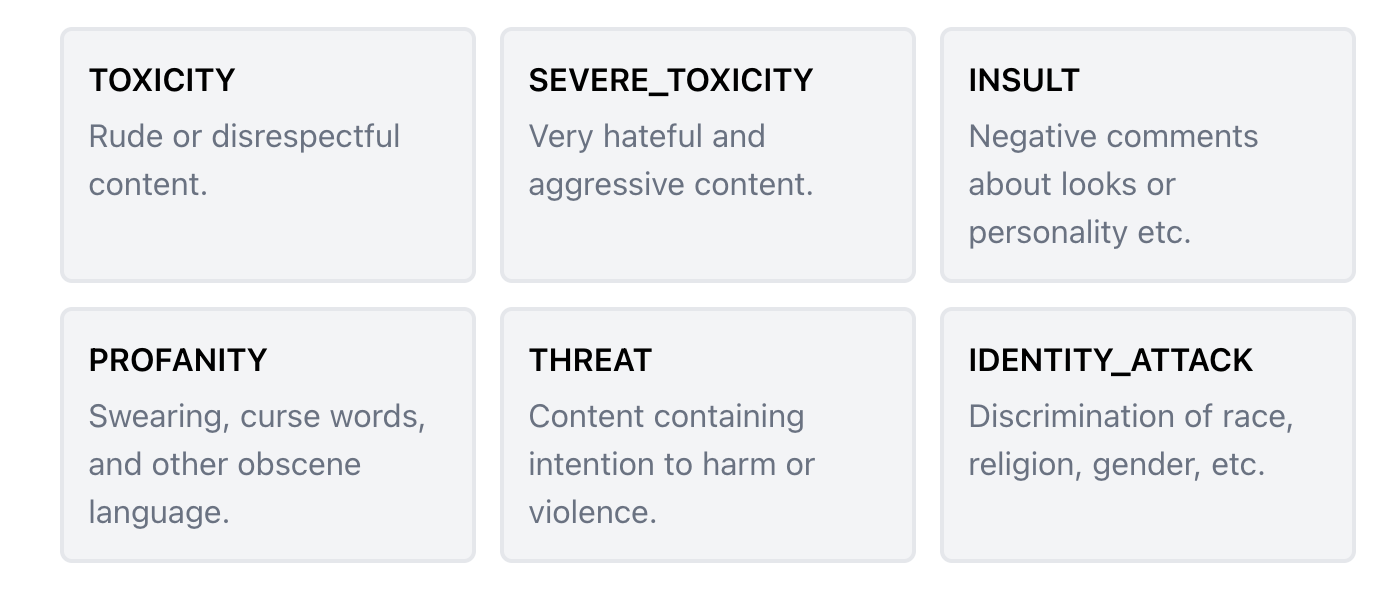
Toxicity Analyzer
If you want to detect and flag a text if it could be toxic this is the model for the job. Contrary to our profanity model, this model can detect more subtle and not so pronounced profane content. If you don't need to block out individual swear words, we recommend using the toxicity analyzer instead of our profanity filter.
Use-cases include:
- Reject comments if they contain severe toxic content.
- Sort comments based on the least toxic, so users mostly see positive content.
- Flag users that generate toxic content for manual moderation.
- Implement automatic warnings in support chats if a message could seem harmful.
Quality Analyzer
When your business depends on user-generated content, you're probably spending time to make sure you highlight the best content. With the quality analyzer, you can automatically highlight high-quality content and block out spam.
Use-cases include:
- Reject form submissions if they're low quality.
- Automatically rate users based on profile text.
- Block spam and self-promotion comments.

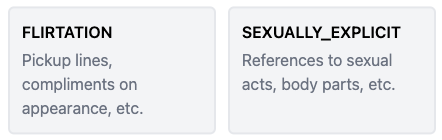
Propriety Analyzer
Chat applications between strangers can quickly go south if one actor is feeling a little too friendly. With the propriety analyzer, you can check if messages contain sexual insinuations or are being flirty.
Use-cases include:
- Evaluate chat behavior and take action if a user is being inappropriate.
- Assess if users are flirting without manually looking at messages and breaking privacy laws.
I hope you'll find the new models useful. If you need help implementing them or need to tweak them, please message us at support@moderationapi.com.
-Christopher