
Custom Guidelines - AI enforced
Your rules, enforced by AI. Just describe them in plain language.
Your rules, enforced by AI. Just describe them in plain language.
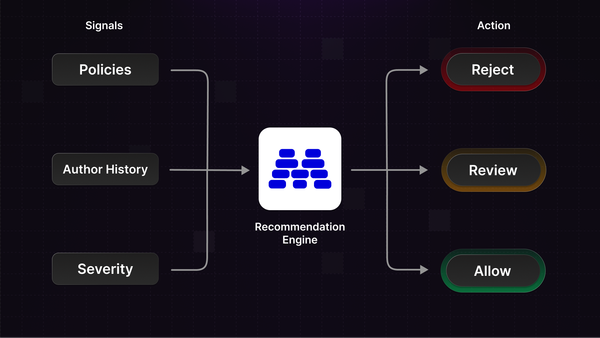
Stop treating every flag the same. Action Recommendations combine trust levels, severity scores, and policy signals to tell you when to allow, review, or reject content.
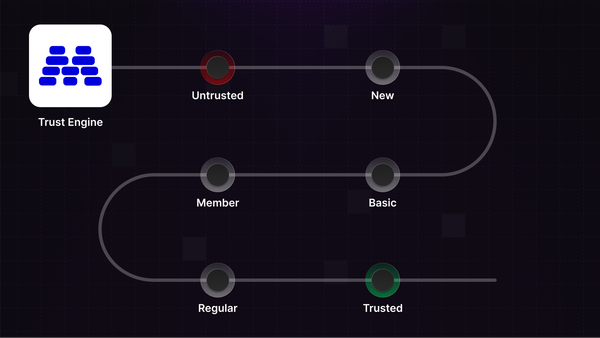
Moderation isn't only about finding bad actors. It's about recognizing who's trustworthy. Introducing Trust Levels.
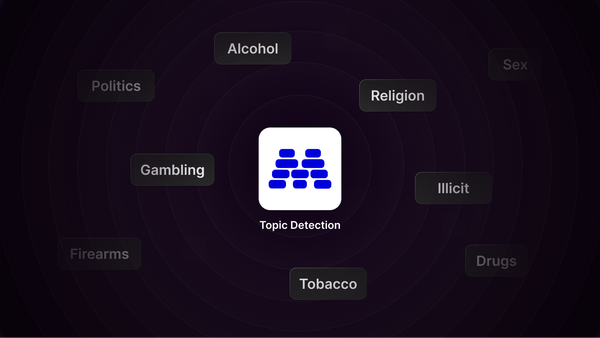
Automatically detect and act on content about sensitive topics like religion, politics, and SHAFT categories.
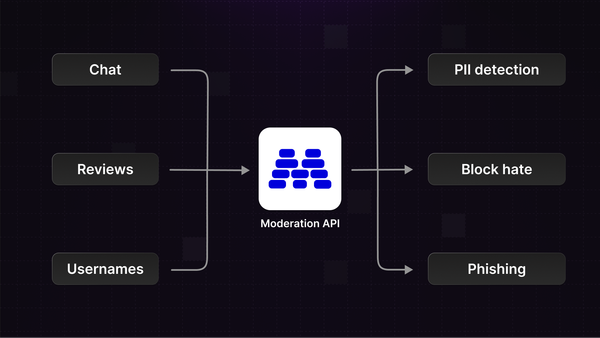
Scale moderation across chat, reviews, and profiles with content channels. Set distinct policies, separate review queues, and improve accuracy by declaring content types.
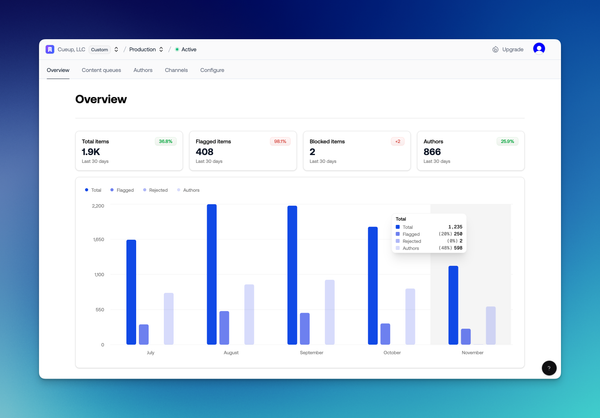
We've shipped two huge upgrades to make Moderation API faster to set up, richer in signal, and easier to maintain - and next week we’re launching something new every day (Dec 8-12). Revamped dashboard Next time you sign in, the dashboard will feel very different. We rebuilt

Users often come across inappropriate content, and it's crucial for social platforms to handle this scenario effectively. Allowing your users to report content builds trust, maintains a safe online environment, and ultimately improves the bottom line. But as your user base grows, managing these reports can become challenging.

Today we just rolled out a suite of new API endpoints designed to improve the experience with our Wordlists and Review Queues for enterprise plans. These enhancements offer greater flexibility if you're aiming to customise your moderation interface and leverage our robust moderation and review queue engine. There&

The new image toxicity model adds a single but robust label for detecting and preventing harmful images. Where the image NSFW model can distinguish between multiple types of unwanted content, it can fail to generalise to toxic content outside of the provided labels. The toxicity model on the other hand

Until now, Moderation API allowed for the moderation of individual pieces of text or images. In practice, there’s often a need to moderate entire entities composed of multiple content fields. While one solution has been to call the API separately for each field, this approach can be inefficient and

You can now add smart wordlists that understand semantic meaning, similar words, and obfuscations in your Moderation API projects. When to use a wordlist In many cases an AI agent is a better solution to enforce certain guidelines as they understand context and intent, but wordlists are useful if you

Llama Guard 3, now on Moderation API, offers precise content moderation with Llama-3.1. It’s faster and more accurate than GPT-4, perfect for real-time use and customizable for nuanced moderation needs.

We are thrilled to kick off 2024 with a host of exciting new features, and we have many more in store for the year ahead. Label Thresholds In your moderation project, you now have the ability to adjust the sensitivity per label, providing fine-grained control over content flagging. Additionally, you

We've just made 4 new classifier models availabel in your dashboards. Sexual model - Moderation APIModeration APIDiscrimination model - Moderation APIModeration APISelf harm model - Moderation APIModeration APIViolence model - Moderation APIModeration API

* New features: * Add your own options to actions. Useful if you need to specify why an action was taken. For example an item was removed because of "Spam", "Innapropriate", etc. * Select specific queues an action should show up in. * Performance improvements: much better reponsiveness and speed

Updates
We have been hard at work to develop new features and enhance the experience with Moderation API. Today, we are incredibly excited to announce: 1. A brand-new feature to create and train custom AI models 🛠 2. A new Sentiment Analysis model 🧠🌟 Introducing Custom Models 🌟 Say hello to the era of

Updates
A new sentiment model just became available in your dashboards. In our evaluations the new model seems to surpass other solutions on the market when understanding underlying sentiment in more complex senteces. This is probably due to the underlying large language model with its remarkable contextual understanding. The model detects

Updates
We've released a new NSFW ("Not Suitable For Work") model for detecting NSFW or otherwise sensitive text. However, it's still in the experimental stage, so we recommend using it alongside your existing models. The model can detect and categorize UNSAFE or SENSITIVE content. It
For security reasons all accounts have a character limit at 10.000 characters pr. request. If you have cases where you need to analyze a big amount of text, you might need to increase this limit. Now you can - just send us a message at support@moderationapi.com. In
I'm excited to announce 3 new models available in the dashboard as of today! In this post, I'll briefly go over each of them and describe some interesting use cases. Each analyzer returns the respective scores of each label and decides on the label with the
As we add more and more models, we saw the dashboard getting more cluttered. To improve and anticipate upcoming features, we've changed to a search interface where you add each model to a project. This makes for a powerful workflow where you can add specific models needed per

We've just published a new model for recognizing a collection of sensitive numbers.
Improvements
We've discovered and fixed an issue where sentences added to word-lists would not be detected properly.
Updates
You will now see a word list tab on the dashboard. You can create multiple word lists that can be used across your filters and analyzers. For example, create a word list for mild swear words that you want to allow in your app, and leave our profanity filter to